OpenAI presentó un modelo de inteligencia artificial capaz de vulnerar sistemas corporativos con una destreza que equipara a la del rival Anthropic. El Instituto de Seguridad de IA del Reino Unido (AISI) confirmó que GPT-5.5 posee capacidades ofensivas idénticas a las de Claude Mythos Preview, según una evaluación publicada el 30 de abril. El hallazgo subraya que la habilidad para infiltrarse en infraestructuras críticas ya no es exclusiva de un solo modelo, sino una característica generalizada en la nueva generación de sistemas de IA.
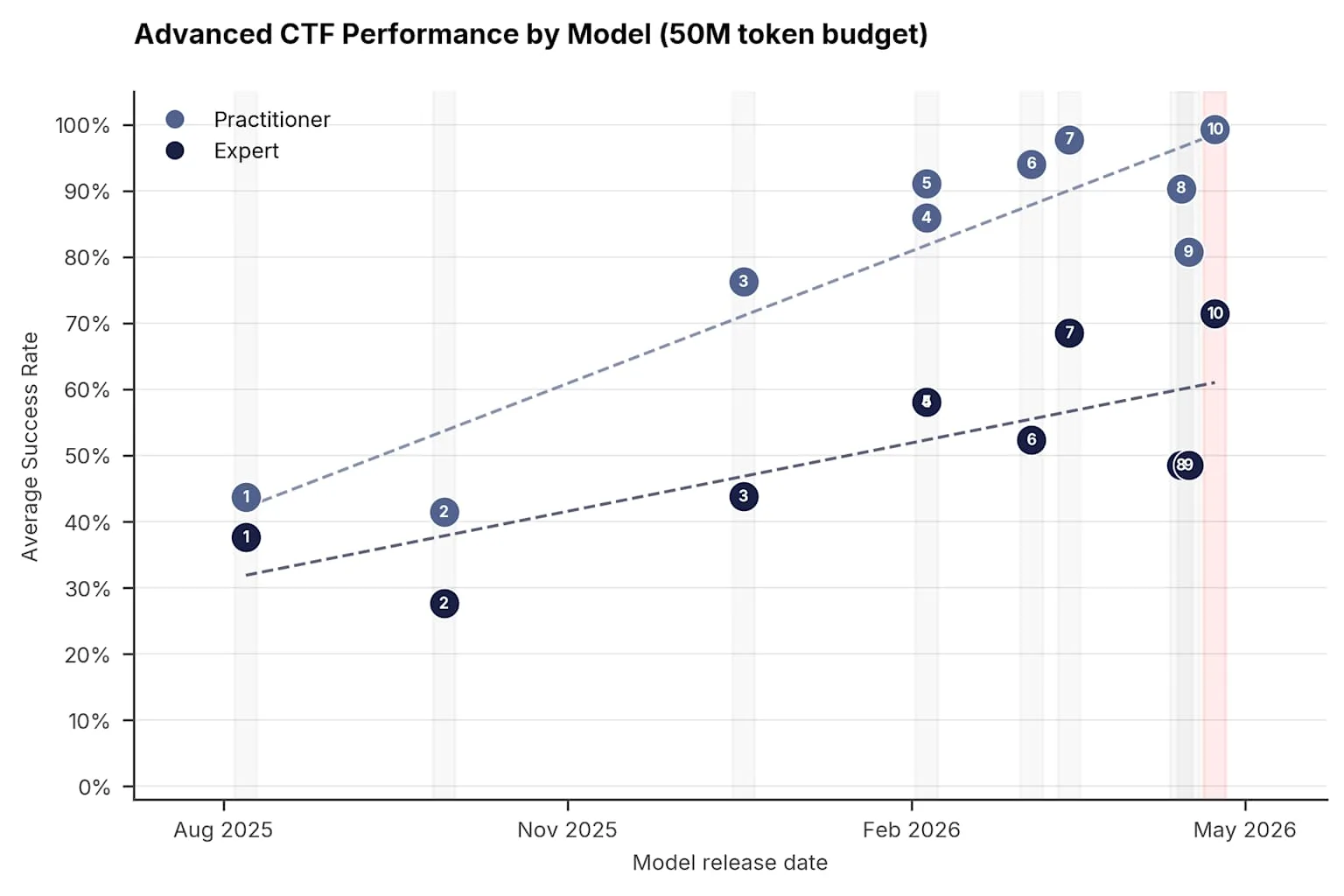
En pruebas extremas que exigían romper algoritmos criptográficos y explotar vulnerabilidades de memoria, GPT-5.5 logró una tasa de éxito del 71.4%, estadísticamente emparejado con el 68.6% de Mythos Preview. Las versiones anteriores quedaron atrás: GPT-5.4 alcanzó 52.4% y Opus 4.7 obtuvo 48.6%. El modelo de OpenAI también se convirtió en la segunda IA capaz de completar una simulación de ataque a redes corporativas de 32 pasos, logrando la hazaña en dos de diez intentos. El tiempo de ejecución resulta inquietante: una tarea de infiltración que a un ingeniero humano requeriría 12 horas de trabajo, la herramienta la completó en menos de 11 minutos con un costo operativo de 1,73 dólares.

Anthropic había cancelado en abril el lanzamiento público de Mythos Preview debido a su capacidad autónoma para identificar exploits de día cero. La empresa restringió el acceso a unas 40 organizaciones verificadas como Apple, Microsoft y JPMorgan Chase, bajo el programa controlado Project Glaswing. OpenAI eligió una estrategia contraria: liberó GPT-5.5 al público el 23 de abril, confiando en sus filtros de seguridad internos para bloquear solicitudes maliciosas. Posteriormente, el CEO Sam Altman anunció la creación de GPT-5.5-Cyber, una variante especializada disponible únicamente para un grupo selecto de defensores de confianza.
El AISI publicó su análisis para clarificar la situación del mercado tecnológico. Los investigadores cuestionaban si el desempeño de Mythos reflejaba un avance específico de un único modelo o parte de una tendencia más amplia. Los resultados sugirieron lo segundo. La advertencia del instituto británico señala un nuevo riesgo: si la destreza en ciberataques crece como efecto secundario del razonamiento de las máquinas, deben esperarse incrementos mayores en la capacidad cibernética de los modelos en el futuro cercano, potencialmente en rápida sucesión.